

États et Actions
En apprentissage par renforcement, l’équation de Bellman décrit une façon de récompenser un agent suite à une action.
Avant tout, il est nécessaire de comprendre que dans un environnement donné, on définit :
- des états : ce sont les différentes configurations de l’environnement. Par exemple, si on considère une grille de jeu de morpion (notre environnement), alors les états sont les différents arrangements possibles de croix et de ronds.
Deux états différents au morpion
Généralement, on associe à chaque état un nombre entier, de 1 à N (nombre total d’états).
Au morpion, il y a théoriquement N = 39 = 19683 états, mais certains n’apparaissent jamais, comme une grille remplie de ronds.
- des actions : ce sont les choix possibles, quel que soit l’état considéré. Au morpion, en considérant le joueur qui place les croix, il y a donc 9 actions possibles, une pour chaque case de la grille. Certaines actions mènent à la victoire ou à la défaite, d’autres font simplement progresser le jeu. Une action « impossible », comme jouer sur une case déjà occupée, amènera à la défaite.
Un tableau de scores : la Q-Table
Pour choisir quelle action effectuer dans un état donné, on utilise un tableau de scores, appelé Q-table (Q pour Qualité) : c’est un tableau à double entrée qui, à chaque paire (état , action) associe un score, positif ou négatif.
Dans un état donné, on choisira alors l’action avec le plus grand score.
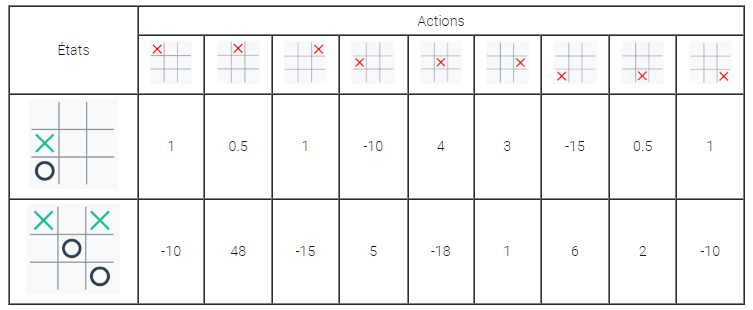
Dans cet exemple, on voit que les actions menant à une victoire sont mieux récompensées que les autres. Quant aux actions « interdites », elles sont fortement punies par un score négatif.
Dans le cas du morpion, la Q-Table contient au plus 39 x 9 = 177 147 cases. C’est beaucoup pour un humain, mais pas pour un ordinateur.
Cependant, dans le cas d’un jeu comme le puissance 4, il y a 7 actions possibles et un maximum théorique de 342 états, soit une Q-Table contenant au maximum 342 x 7 = 765932923920586514463 cases !
Le problème qui se pose alors est : comment remplir correctement et efficacement la Q-Table ? C’est là qu’intervient l’équation de Bellman.
Q-Table et équation de Bellman
Quelques explications s’imposent :
- représente un état, une action et le score associé au couple (état, action)
- et sont des paramètres d’apprentissage, nommés respectivement la vitesse d’apprentissage et le facteur d’actualisation
- R est la récompense associée à l’action dans l’état , et prend en général au moins 3 valeurs :
- une valeur en cas de victoire, comme +10
- une valeur en cas de défaite, comme -10
- une valeur par défaut, lorsque le jeu continue, comme -1
- représente le score maximum que l’on peut obtenir depuis l’état , suivant l’état après l’action .
On peut réécrire cette équation de la façon suivante :
Un cas particulier est celui où : on « oublie » le score précédent , et on met à jour la Q-Table uniquement avec la récompense R et le score « futur » maximum :
Avec cette dernière formule, on voit bien le rôle de : plus l’état est intéressant pour gagner, plus ce maximum sera grand et la valeur de augmentée en conséquence, indiquant qu’effectuer l’action dans l’état est une bonne solution. Inversement, moins cet état est intéressant et moins augmentera.